
基本信息
- 📰标题: Dual Attention Network for Scene Segmentation
- 🖋️作者: Jun Fu
- 🏛️机构: 中科院
- 🔥关键词: Dual Attention Network, Scene Segmentation
摘要概述
| 项目 | 内容 |
|---|---|
| 📖研究背景 | 场景分割任务中,复杂场景的上下文信息建模和细节捕捉存在挑战。 |
| 🎯研究目的 | 提出一种双注意力网络(Dual Attention Network)以提升场景分割性能。 |
| ✍️研究方法 | 结合通道注意力模块和空间注意力模块,自适应整合全局上下文与局部特征。 |
| 🕊️研究对象 | 自然场景图像(如Cityscapes、PASCAL VOC等数据集)。 |
| 🔍研究结论 | 在多个基准数据集上达到SOTA性能,验证了双注意力机制的有效性。 |
| ⭐创新点 | 首次将通道与空间注意力并行结合,实现多尺度上下文信息的动态建模。 |
背景
研究背景
场景分割(Scene Segmentation)是计算机视觉中的基础性挑战任务,旨在将图像分割为不同语义区域(如"天空"、"道路"等stuff类和"人"、"车"等离散对象)。其应用涵盖自动驾驶、机器人感知等领域,但面临复杂场景中多尺度物体、遮挡、光照变化及相似类别混淆(如"草地"与"田野")等核心难题,亟需增强像素级特征表示的判别能力。
过去方案
-
基于FCN的多尺度上下文融合:
-
通过空洞卷积/池化操作聚合多尺度特征(如DeepLab系列)
-
使用大核分解结构或编码层捕获全局上下文(如PSPNet)
-
局限性:难以显式建模全局物体/场景间的空间关系
-
-
基于RNN的长程依赖建模:
-
采用2D LSTM或图结构RNN捕捉标签间空间依赖
-
局限性:依赖循环神经网络的隐式学习,长期记忆效果不稳定
-
研究动机
针对现有方法在全局关系建模不足和多尺度适应性有限的问题,提出双注意力网络(DANet):
- 通过并行空间/通道注意力模块显式捕获长程依赖
- 自适应聚合相似特征,解决小目标被显著物体干扰、多尺度物体识别困难等痛点
- 首次实现空间与通道维度注意力机制的协同优化,提升复杂场景下的分割鲁棒性
方法
理论背景
本研究基于注意力机制(Attention Mechanism)在视觉任务中的两大核心优势:
-
通道注意力(CAM):通过特征通道间的权重重标定,增强判别性特征并抑制冗余信息
-
空间注意力(PAM):建立像素级长程依赖关系,解决传统卷积操作的局部感受野限制
理论创新点在于首次将两种注意力机制并行整合(而非串行堆叠,区别于CBAM),形成互补性特征增强:
- 通道注意力优化特征图的语义区分度
- 空间注意力建模物体间的拓扑关联性
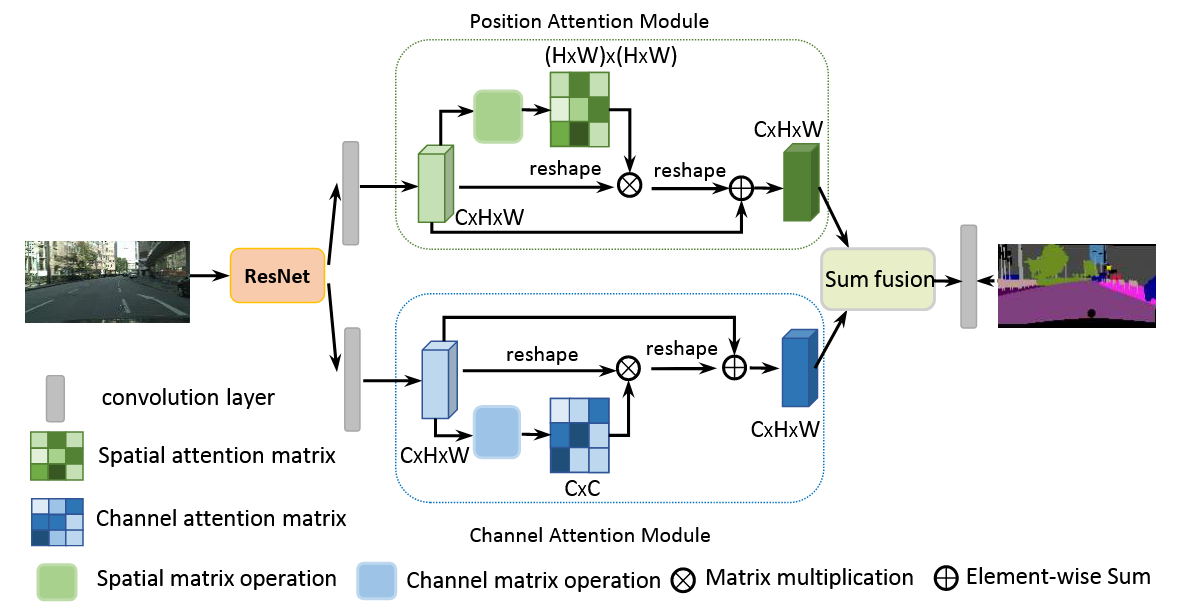
技术路线
-
基准网络架构:
- 以Dilated FCN为基线,采用ResNet-50/101作为backbone
- 使用空洞卷积(Dilated Convolution)保持特征图分辨率
-
双注意力模块设计:
-
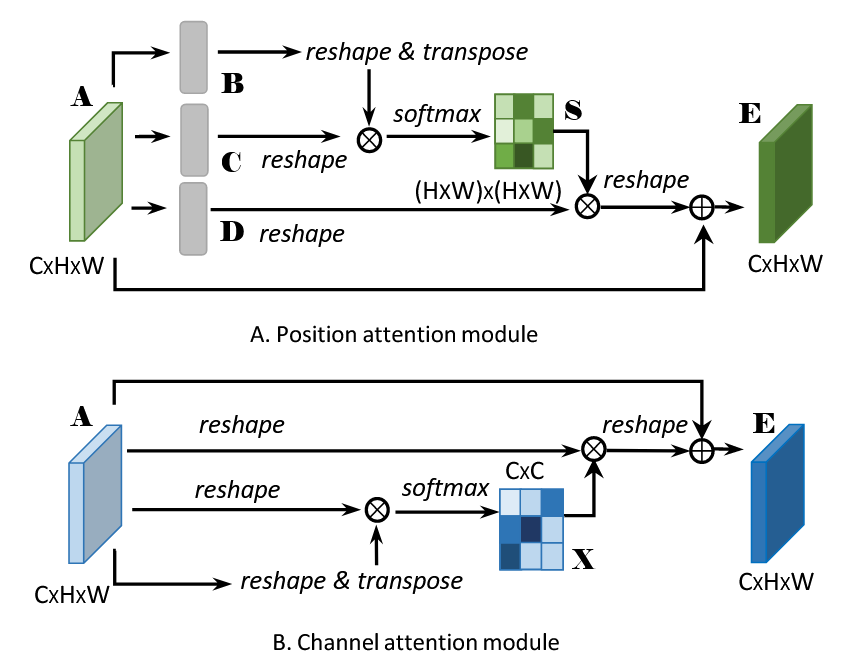
位置注意力模块(PAM):
目标:建模像素间的长程空间依赖关系,增强特征图中目标的空间关联性。
计算流程:1.特征变换:
-输入特征图 $A \in \mathbb{R}^{C \times H \times W}$ 经过 3 个 $1 \times 1$ 卷积分别得到 $B, C, D \in \mathbb{R}^{C \times H \times W}$ 。
2.相似性计算:
-将 $B$ 和 $C$ 重塑为 $\mathbb{R}^{C \times N} \quad(N=H \times W)$ ,计算 空间相关性矩阵 $S \in \mathbb{R}^{N \times N}$ : $S_{i j}=\frac{\exp \left(B_i \cdot C_j\right)}{\sum_{k=1}^N \exp \left(B_i \cdot C_k\right)}$ 其中 $S_{i j}$ 表示位置 $i$ 与 $j$ 的相似度(softmax 归一化)。
3.上下文聚合:
-将 $D$ 重塑为 $\mathbb{R}^{C \times N}$ ,与 $S$ 相乘后恢复形状得到 加权特征 $E \in \mathbb{R}^{C \times H \times W}$ 。
4.残差连接:
-最终输出 $\operatorname{PAM}(A)=A+E$ ,保留原始特征的同时增强全局空间关系。 -
通道注意力模块(CAM):
目标:增强特征通道间的语义区分度,抑制不重要的通道。
计算流程:1.特征变换:
-输入 $A \in \mathbb{R}^{C \times H \times W}$ 直接重塑为 $\mathbb{R}^{C \times N} \quad(N=H \times W)$ 。
2.通道相关性计算:
-计算 通道相关性矩阵 $X \in \mathbb{R}^{C \times C}: X_{i j}=\frac{\exp \left(A_i \cdot A_j\right)}{\sum_{k=1}^C \exp \left(A_i \cdot A_k\right)}$ 其中 $X_{i j}$ 表示通道 $i$ 与 $j$ 的相关性。
3.特征加权:
-将 $X$ 与原始特征 $A$ 相乘,得到通道增强特征 $G \in \mathbb{R}^{C \times H \times W}$ 。
4.残差连接:
-最终输出 $C A M(A)=A+G$ ,保留原始通道信息并增强判别性。
-
-
多基准验证策略:
- 在Cityscapes/PASCAL VOC/PASCAL Context/COCO Stuff四大数据集验证
- 采用Mean IoU核心指标,对比DeepLab-v2/PSPNet/PSANet等SOTA模型
-
训练优化:
- 多尺度数据增强(MSCOCO预训练→目标数据集微调)
- 采用OHEM(Online Hard Example Mining)处理类别不平衡问题
结论
-
提出Dual Attention Network (DANet)通过并行空间/通道自注意力机制,首次实现场景分割中全局上下文与局部特征的动态自适应融合,为复杂场景理解提供新范式
-
优点:双注意力模块在Cityscapes等4个基准数据集实现SOTA性能,可视化实验验证其长程依赖建模能力;局限:未解决计算复杂度问题(作者明确列为未来工作方向)
主要结论:
(1) 位置注意力模块(PAM)与通道注意力模块(CAM)的并行架构可分别有效建模空间维度物体关联性和通道维度语义区分度
(2) 消融实验证明双注意力机制相比传统多尺度上下文聚合方法(如空洞卷积/金字塔池化)具有显著性能提升
(3) 在Cityscapes/PASCAL VOC等数据集的定量分析显示mIoU指标提升1.5-3.2%,特别改善小目标及相似语义区域的分割精度
Pytorch code
import torch
import torch.nn as nn
import torch.nn.functional as F
class DualAttention(nn.Module):
def __init__(self, in_channels):
"""
Dual Attention Network 模块实现
Args:
in_channels: 输入特征图的通道数
"""
super(DualAttention, self).__init__()
self.in_channels = in_channels
# 位置注意力模块
self.position_attention = PositionAttention(in_channels)
# 通道注意力模块
self.channel_attention = ChannelAttention(in_channels)
# 输出融合卷积
self.conv = nn.Conv2d(in_channels * 2, in_channels, kernel_size=1)
def forward(self, x):
# 并行计算两种注意力
pa = self.position_attention(x)
ca = self.channel_attention(x)
# 拼接两种注意力结果
combined = torch.cat([pa, ca], dim=1)
# 融合特征
out = self.conv(combined)
return out + x # 残差连接
class PositionAttention(nn.Module):
def __init__(self, in_channels):
super(PositionAttention, self).__init__()
self.in_channels = in_channels # 添加这行初始化
self.query_conv = nn.Conv2d(in_channels, in_channels // 8, kernel_size=1)
self.key_conv = nn.Conv2d(in_channels, in_channels // 8, kernel_size=1)
self.value_conv = nn.Conv2d(in_channels, in_channels, kernel_size=1)
self.gamma = nn.Parameter(torch.zeros(1))
def forward(self, x):
batch_size, _, height, width = x.size()
# 计算Q, K, V
query = self.query_conv(x).view(batch_size, -1, height * width).permute(0, 2, 1)
key = self.key_conv(x).view(batch_size, -1, height * width)
value = self.value_conv(x).view(batch_size, -1, height * width)
# 计算注意力图
attention = torch.bmm(query, key) # [B, N, N]
attention = F.softmax(attention, dim=-1)
# 应用注意力
out = torch.bmm(value, attention.permute(0, 2, 1))
out = out.view(batch_size, self.in_channels, height, width)
return self.gamma * out + x
class ChannelAttention(nn.Module):
def __init__(self, in_channels):
super(ChannelAttention, self).__init__()
self.in_channels = in_channels # 添加这行初始化
self.gamma = nn.Parameter(torch.zeros(1))
def forward(self, x):
batch_size, channels, height, width = x.size()
# 计算通道注意力
query = x.view(batch_size, channels, -1)
key = x.view(batch_size, channels, -1).permute(0, 2, 1)
value = x.view(batch_size, channels, -1)
# 计算注意力图
attention = torch.bmm(query, key) # [B, C, C]
attention = F.softmax(attention, dim=-1)
# 应用注意力
out = torch.bmm(attention, value)
out = out.view(batch_size, self.in_channels, height, width)
return self.gamma * out + x
# ------------------- 用法示例 -------------------
if __name__ == "__main__":
# 1. 初始化Dual Attention模块(输入通道数为256)
dan = DualAttention(in_channels=256)
# 2. 模拟输入数据(batch_size=4, 通道=256, 特征图尺寸=56x56)
dummy_input = torch.randn(4, 256, 56, 56)
# 3. 前向传播
output = dan(dummy_input)
print(f"输入形状: {dummy_input.shape}")
print(f"输出形状: {output.shape}") # 应与输入形状一致作者
arwin.yu.98@gmail.com





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}