
基本信息
-
📰标题: SA-NET: SHUFFLE ATTENTION FOR DEEP CONVOLUTIONAL NEURAL NETWORKS
-
🖋️作者: Qing-Long Zhang
-
🏛️机构: State Key Laboratory for Novel Software Technology at Nanjing University(南京大学计算机软件新技术国家重点实验室)
-
🔗链接: SA-Net GitHub
-
🔥关键词: spatial attention, channel attention, channel shuffle, grouped features
摘要概述
| 项目 | 内容 |
|---|---|
| 📖研究背景 | 注意力机制(spatial/channel attention)已成为提升深度神经网络性能的关键组件,但融合二者会显著增加计算开销。 |
| 🎯研究目的 | 提出高效Shuffle Attention(SA)模块,以低计算成本整合两种注意力机制。 |
| ✍️研究方法 | 分组通道特征→并行处理→Shuffle Unit建模空间/通道依赖→通道混洗实现跨组信息交互。 |
| 🕊️研究对象 | ImageNet-1k(分类)、MS COCO(目标检测/实例分割)等基准数据集。 |
| 🔍研究结论 | SA在ResNet50上仅增加300参数/2.76e-3 GFLOPs,Top-1准确率提升>1.34%,模型复杂度低于SOTA方法。 |
| ⭐创新点 | 通过分组和通道混洗实现高效特征交互,平衡性能与计算效率。 |
背景
-
研究背景:注意力机制(channel/spatial attention)通过增强关键特征抑制噪声,显著提升计算机视觉任务性能,但现有方法难以高效融合两种注意力。
-
过去方案:
-
混合式:GCNet/CBAM等融合双注意力但存在计算复杂度高、收敛困难问题;
-
简化式:ECA-Net简化channel attention计算,SGE分组处理spatial attention,但均未充分利用双注意力协同效应。
-
-
研究动机:基于ShuffleNet多分支并行与SGE分组策略,提出轻量化Shuffle Attention模块,通过分组特征与通道混洗实现高效双注意力融合,解决性能与计算效率的平衡问题。
方法
-
理论背景:
基于注意力机制中channel attention与spatial attention的互补性,借鉴ShuffleNet的group convolution与channel shuffle思想,提出通过特征分组并行处理实现双注意力高效协同。理论核心在于:
1) 分组特征可降低计算复杂度;
2) 通道混洗(channel shuffle)能保持跨组信息交互;
3) 并行分支结构可保留空间-通道注意力独立性。 -
技术路线:
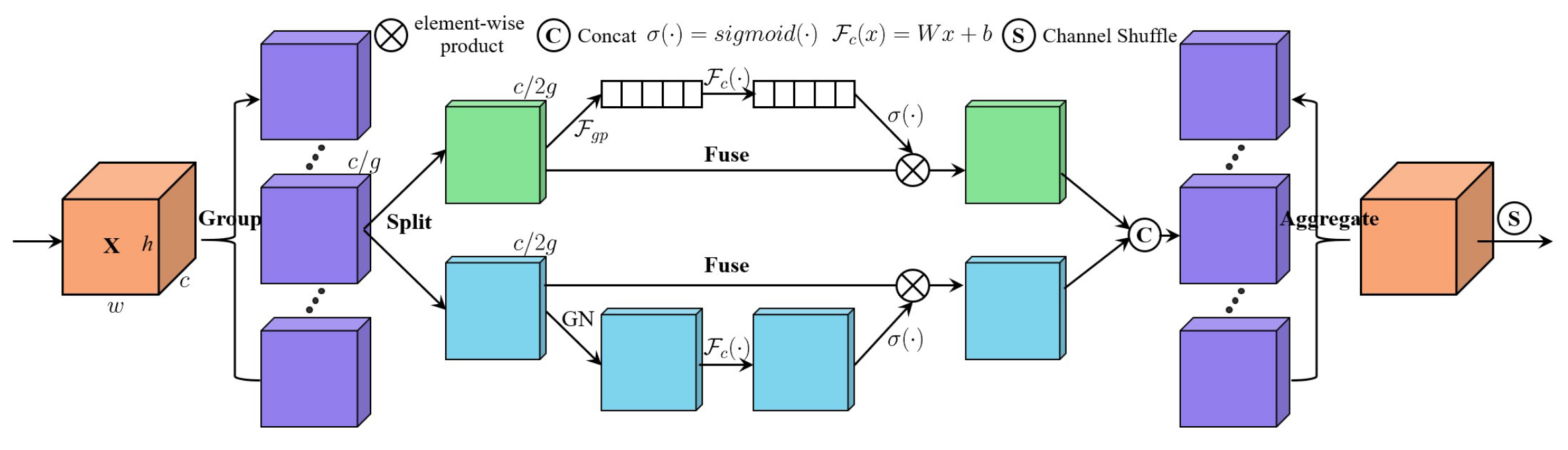
1.模块输入与特征分组 -
输入特征图:模块接收输入特征图 $X \in \mathbb{R}^{C \times H \times W}$ ,其中 $C$ 为通道数,$H \times W$ 为空间尺寸。
-
分组策略:沿通道维度将 $X$ 划分为 $G$ 组(默认 $G=64$ ),每组子特征 $X_k \in \mathbb{R}^{C / G \times H \times W}$ 。
2.并行双分支注意力机制
每个子特征 $X_k$ 进一步拆分为两个分支(各 $C / 2 G$ 通道),分别处理通道注意力和空间注意力:
(a)通道注意力分支
- 全局池化:通过全局平均池化(GAP)生成通道统计量 $s \in \mathbb{R}^{C / 2 G \times 1 \times 1}$ ,压缩空间信息)。
- 自适应校准:使用可学习的缩放参数 $W_1$ 和偏置 $b_1$ 调整通道权重,通过Sigmoid激活生成注意力掩码。
- 轻量化设计:相比SENet的FC层,参数量更少
(b)空间注意力分支
- 归一化:对输入 $X_{k 2}$ 应用组归一化(Group Norm)[Wu and He(2018)[25]],稳定训练并增强空间分布一致性。
- 空间权重生成:类似通道分支,通过可学习参数 $W_2$ 和 $b_2$ 生成空间注意力图。
- 互补性:空间注意力聚焦“何处重要”,与通道注意力的“何通道重要”形成互补。
3.特征聚合与通道混洗
- 分支拼接:将两个分支输出沿通道维度拼接为 $X_k^{\prime} \in \mathbb{R}^{C / G \times H \times W}$ 。
- 跨组信息交互:通过通道混洗(Channel Shuffle)[详见ShuffleNet]打乱组间通道顺序,促进不同子特征间的信息流动(根据实验验证,混洗带来 $0.4 \%$ 精度提升)。
4. 模块输出与整体流程
- 输出尺寸:最终输出与输入尺寸相同,可直接嵌入现有CNN架构(如ResNet)。
- 效率对比:SA模块仅增加0.002M参数(ResNet50为例),FLOPs几乎不变,但Top-1精度提升1.34% [1, Table 1]。
结论
-
提出轻量化Shuffle Attention(SA)模块,通过分组并行处理与通道混洗机制,在几乎不增加计算成本(仅2.76e-3 GFLOPs)的前提下,有效融合spatial/channel双注意力,显著提升CNN特征表达能力
-
优点:
1) 采用分组策略与Shuffle Unit实现计算高效性;
2) 模块化设计兼容主流CNN架构; -
缺点:未讨论极端分组数(如G=1或G=C)对性能的影响
-
主要结论:
(1) SA模块通过分组特征→并行处理→通道混洗的三阶段设计,实现跨维度注意力协同;
(2) 在ResNet50等基准模型上验证其有效性(Top-1准确率提升>1.34%),且参数量仅增加300;
(3) 未来将扩展至ShuffleNet/SKNet等轻量化架构
作者
arwin.yu.98@gmail.com





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}