
基本信息
- 📰标题: Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
- 🖋️作者: Ze Liu
- 🏛️机构: Microsoft Research Asia (微软亚洲研究院)
- 🔥关键词: Vision Transformer, Hierarchical Architecture, Shifted Windows, Self-Attention
摘要概述
| 项目 | 内容 |
|---|---|
| 📖研究背景 | Vision Transformer(ViT)在图像分类中表现优异,但高分辨率图像计算复杂度高,且缺乏多尺度建模能力。 |
| 🎯研究目的 | 提出一种高效且通用的视觉Transformer骨干网络,支持密集预测任务(如检测和分割)。 |
| ✍️研究方法 | 设计分层架构(Hierarchical Architecture)和移位窗口自注意力(Shifted Window Self-Attention)。 |
| 🕊️研究对象 | 图像分类(ImageNet)、目标检测(COCO)、语义分割(ADE20K)任务。 |
| 🔍研究结论 | Swin Transformer在计算效率和性能上优于ViT和CNN,COCO检测AP达58.7(Swin-L)。 |
| ⭐创新点 | 1. 移位窗口机制实现跨窗口信息交互;2. 分层结构支持多尺度特征;3. 线性计算复杂度。 |
背景
-
研究背景:
计算机视觉建模长期由CNN主导(如AlexNet),而NLP领域则以Transformer为主流。尽管Transformer在语言任务中表现卓越,但其直接应用于视觉任务面临两大挑战:1) 视觉元素尺度多变,而传统Transformer采用固定尺度的token;2) 高分辨率图像(如语义分割)导致全局自注意力计算复杂度呈平方级增长。 -
过去方案:
-
CNN(如ResNeXt):通过复杂卷积结构提升性能,但缺乏全局建模能力。
-
Vision Transformer(ViT):虽在图像分类中表现优异,但存在单分辨率特征图(无法适应多尺度任务)和二次方计算复杂度(难以处理高分辨率图像)的缺陷。
-
滑动窗口自注意力(如局部注意力机制):计算效率低,硬件延迟高。
- 研究动机:
为解决Transformer在视觉任务中的局限性,提出Swin Transformer:
1) 通过分层架构(逐步合并图像块)支持多尺度特征;
2) 采用移位窗口自注意力(Shifted Window)实现跨窗口交互,将计算复杂度降至线性;
3) 构建通用视觉骨干网络,统一图像分类与密集预测任务(如检测、分割)的架构需求。
方法
-
理论背景:
本研究基于视觉Transformer架构,针对传统Vision Transformer(ViT)在高分辨率图像处理中的计算复杂度高( $O(N^2)$ )和缺乏多尺度建模能力两大核心问题,提出改进方案。受CNN分层架构启发,结合局部窗口自注意力(Local Window Self-Attention)与跨窗口交互机制,构建高效且通用的视觉骨干网络。 -
技术路线:
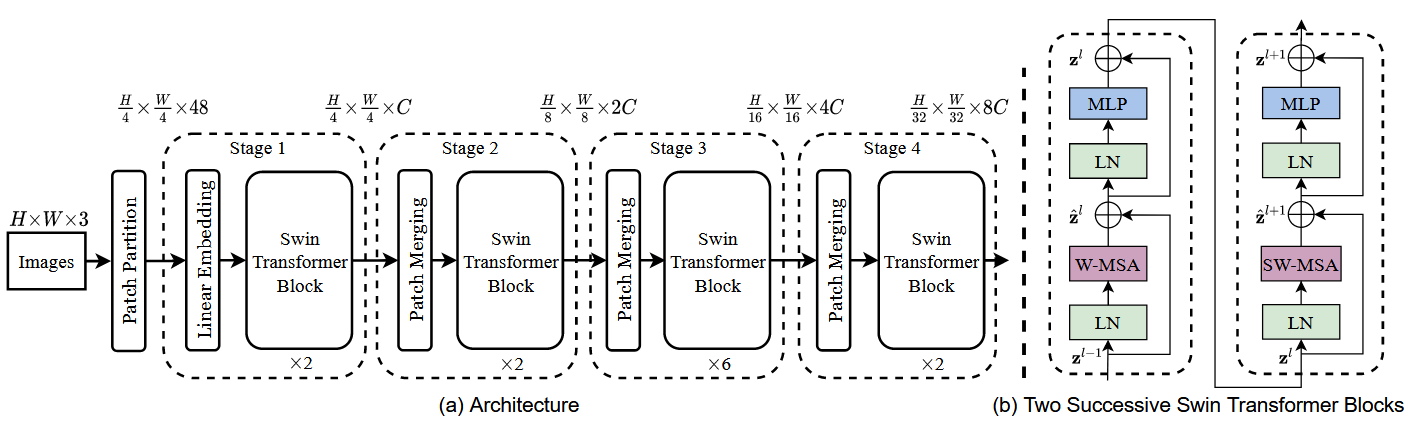
简单看下原论文中给出的关于Swin Transformer网络的结构图,如下图所示。首先将图片输入到Patch Partition模块中进行分块,即每4x4相邻的像素为一个Patch,然后在通道维度上展平。假设输入的是RGB三通道图片,那么每个Patch就有个4x4=16像素,然后每个像素有R、G、B三个值所以展平后数据维度是16x3=48,所以通过Patch Partition后图像张量的形状由[H,W,3]变成了[H/4,W/4,48]。然后再通线性嵌入层对每个像素的通道数据做线性变换,由48变成C,即图像张量的形状再由[H/4,W/4,48]变成了[H/4,W/4,C]。其实在源码中Patch Partition和线性嵌入操作就是直接通过一个卷积层实现的,和之前ViT模型中的Embedding层结构一模一样。
接下来,Swim Transformer模型通过四个Stage构建不同尺寸的特征图。Stage1先通过一个Linear Embedding层,而剩下的三个Stage都会先使用Patch Merging层进行下采样。然后重复堆叠Swin Transformer Block,注意这里的Block实际上有两种结构,如图6-28(b)所示,它们的不同之处仅在于一个使用W-MSA结构,另一个使用SW-MSA结构。这两种结构是成对使用的,先使用一个W-MSA结构,然后使用一个SW-MSA结构,因此堆叠Swin Transformer Block的次数都是偶数。最后,分类网络会接上一个LN层、全局池化层以及全连接层,以得到最终输出。这里并未在顶层图中给出。
接下来,分别详细介绍Patch Merging、W-MSA、SW-MSA以及使用到的相对位置偏置(Relative Position Bias)。需要注意的是,Swin Transformer Block中的MLP结构和Vision Transformer中的结构是一样的。
Patch Merging详解
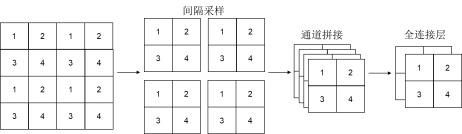
在每个Stage中首先要通过一个Patch Merging层进行下采样(Stage 1除外),此操作的目的是将特征信息从空间维度转移到通道维度。假设输入Patch Merging的是一个4x4大小的单通道特征图,以特征图左上角的四个元素为起点,通过间隔采样得到四个子特征图,然后将这四个子特征在通道维度上进行拼接,再通过一个LN层。最后通过一个全连接层在特征图的深度方向做线性变换,将特征图的深度由C变成C/2,如下图所示。通过这个简单的例子可以看出,经过Patch Merging层后,特征图的高和宽会减半,深度会翻倍。
W-MSA详解
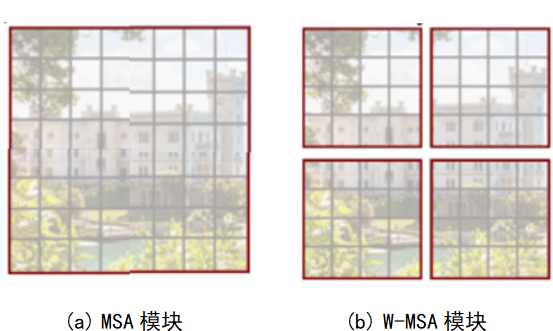
引入W-MSA模块是为了减少计算量。普通的MSA模块如图6-30(a)所示,对于特征图中的每个像素,在自注意力计算过程中需要和所有的像素去计算。在使用W-MSA模块时,首先将特征图按照 MxM 的大小划分成一个窗口(例子中的M=4),然后单独对每个Windows内部进行自注意力计算。
两者的计算量具体差多少呢?原论文中有给出下面两个公式,这里忽略了 Softmax 函数的计算复杂度:
$$
\begin{gathered}
\Omega(\mathrm{MSA})=4 h w C^2+2(h w)^2 C \
\Omega(\mathrm{~W}-\mathrm{MSA})=4 h w C^2+2 M^2 h w C
\end{gathered}
$$
其中,$h$ 代表 feature map 的高度,$w$ 代表 feature map 的宽度,$C$ 代表 feature map 的深度, $M$ 代表每个窗口的大小。假设特征图的 $h 、 w$ 都为 $64, M=4, C=96$ 。采用多头注意力(MSA)模块的计算复杂度为 $4 \times 64 \times 64 \times 962+2 \times(64 \times 64)^2 \times 96=3372220416$ 而采用 W-MSA 模块的计算复杂度为 $4 \times 64 \times 64 \times 962+2 \times 42 \times 64 \times 64 \times 96=163577856$ ,节省了 $95 \%$ 的计算复杂度。
SW-MSA详解
使用W-MSA模块时,只会在每个窗口内进行自注意力计算,因此窗口与窗口之间无法进行信息传递。为了解决这个问题,作者引入了SW-MSA模块,即进行偏移的W-MSA。计算自注意力机制前,窗口发生了偏移,可以理解成窗口从左上角分别向右侧和下方各偏移了M/2个像素。
在此情况下,观察下图展示的Layer1+1层可以发现,对于第一行第二列2x4的窗口,它可以使Layer1层第一排的两个4x4大小的窗口之间进行信息进行交流。同样的道理,对于Layer1+1第二行第二列4x4的窗口,它可以促进Layer1层中四个窗口之间的信息交流。其它窗口的情况也是如此。这解决了不同窗口之间无法进行信息交流的问题。
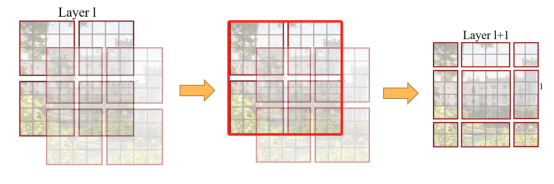
根据上图,可以发现通过将窗口进行偏移后,就到达了窗口与窗口之间的相互通信。虽然已经能达到窗口与窗口之间的通信,但是原来的特征图只有4个窗口,经过移动窗口后,得到了9个窗口,窗口的数量有所增加并且9个窗口的大小也不是完全相同,这就导致计算难度增加。因此,作者又提出了Efficient batch computation for shifted configuration,一种更加高效的计算方法,如下图所示:
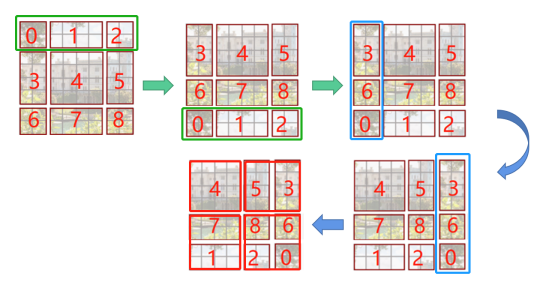
先将 “012”区域移动到最下方,再将 “360”区域移动到最右方,此时移动完后,区域“4”成为了一个单独的窗口,再将区域“5”和“3”合并成一个窗口;“7”和“1”合并成一个窗口;“8”、“6”、“2”和“0”合并成一个窗口。这样又和原来一样变为4个的窗口了,就能够保证计算量的一致,然后分别在每个窗口内进行自注意力计算操作来提取特征,这样可以更有效地利用GPU并行计算的加速效果。但是把不同的区域合并在一起(比如5和3)进行MSA,从逻辑上讲是不合理的,因为这两个区域并不应该相邻。为了防止这个问题,在实际计算中使用的是带蒙板的MSA(Masked MSA),这样就能够通过设置蒙板来隔绝不同区域的信息了。
关于mask如何使用,先回顾常规的MSA计算过程,可以发现,其在最后输出时要经过Softmax操作,Softmax在输入很小时,其输出几乎为0。以上图的区域“5”和区域“3”合并后的区域“53”为例,如果某像素是属于区域5的,我们只想让它和区域“5”内的像素进行匹配。为了实现这个目标,可以将该像素与区域“3”中的所有像素进行注意力计算时,将计算结果减去100。这样,在经过Softmax之后,对应的权重就会接近于0。因此,对于该像素而言,实际上只与区域“5”内的像素进行了MSA。对于其它像素也是同理。需要注意的是,在计算结束后,还需要将数据移回到原来的位置上。
结论
-
提出Swin Transformer作为新型视觉Transformer架构,通过分层特征表达和线性计算复杂度突破ViT在高分辨率图像处理中的局限性,为视觉与语言信号的统一建模提供新范式。
-
优点:
1) 分层结构实现多尺度特征提取;
2) 移位窗口机制在保持线性复杂度的同时实现全局建模;
3) 在COCO和ADE20K任务上显著超越SOTA方法。缺点:未明确讨论小样本场景下的泛化能力或动态分辨率适配性。主要结论:
- 提出具有层次化架构的Swin Transformer,其计算复杂度与输入图像尺寸呈线性关系;
- 在COCO目标检测和ADE20K语义分割任务上达到SOTA性能,验证了架构通用性;
- 为视觉与语言信号的统一建模开辟了新研究方向。
作者
arwin.yu.98@gmail.com




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}