
基本信息
- 📰标题: CBAM: Convolutional Block Attention Module
- 🖋️作者: Sanghyun Woo
- 🏛️机构: Korea Advanced Institute of Science and Technology (KAIST, 韩国科学技术院)
- 🔥关键词: Attention mechanism, CNN, channel attention, spatial attention
摘要概述
| 项目 | 内容 |
|---|---|
| 📖研究背景 | 现有CNN架构缺乏显式建模特征通道和空间位置重要性的机制 |
| 🎯研究目的 | 提出轻量级通用注意力模块,增强CNN的特征表达能力 |
| ✍️研究方法 | 设计串联的Channel Attention Module和Spatial Attention Module |
| 🕊️研究对象 | 图像分类网络(ResNet等)和目标检测网络(Mask R-CNN等) |
| 🔍研究结论 | 在ImageNet分类和COCO检测任务中显著提升性能,且计算开销可忽略 |
| ⭐创新点 | 1. 联合通道-空间注意力机制2. 即插即用设计3. 优于SENet等基线 |
背景
-
研究背景
CNN通过深度、宽度和组数(cardinality)的优化显著提升了视觉任务性能,但现有架构缺乏对特征通道和空间位置重要性的显式建模机制。注意力机制在增强特征表示方面具有潜力,但如何有效整合到CNN中仍需探索。 -
过去方案
-
结构优化:
-
深度:ResNet通过残差连接构建极深架构
-
宽度:Wide ResNet证明增加宽度可超越超深网络
-
组数:ResNeXt显示基数提升比深度/宽度更高效
-
-
存在问题:
- 上述方法未显式建模特征重要性
- 注意力机制(如SENet)仅考虑通道维度,忽略空间信息
- 研究动机
提出轻量级Convolutional Block Attention Module(CBAM),通过通道-空间双注意力机制动态增强关键特征并抑制噪声,实现:
- 即插即用的通用性
- 联合优化"what"(通道)和"where"(空间)注意力
- 在分类/检测任务中同步提升性能与可解释性
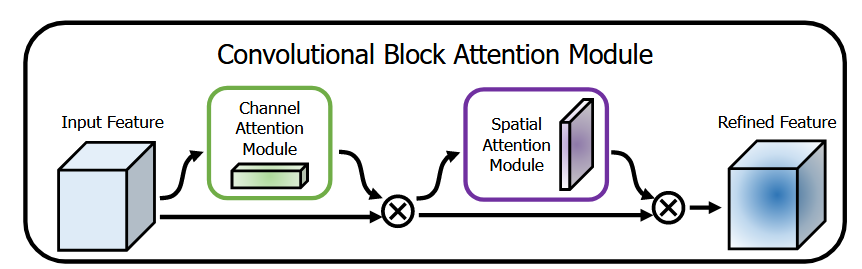
方法
- 理论背景
本研究基于特征重标定(feature recalibration)理论,认为CNN的特征优化需同时考虑通道域(channel-wise)和空间域(spatial-wise)的注意力机制。受SENet通道注意力启发,提出通道与空间注意力存在互补性:通道注意力解决"what to focus"(语义重要性),空间注意力解决"where to focus"(位置显著性),二者串联可实现更精细的特征选择。如下图所示:
- 详细技术路线
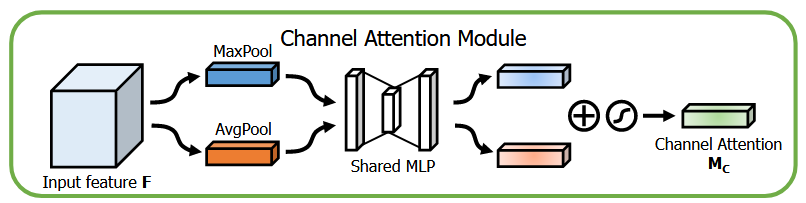
Channel Attention Module(通道注意力模块)
原理:
通道注意力模块旨在通过动态调整特征图各通道的权重,突出重要语义特征并抑制冗余信息。其核心步骤如下:
1.双路空间压缩:
-对输入特征图 $F \in \mathbb{R}^{C \times H \times W}$ 分别进行全局平均池化(GAP)和全局最大池化(GMP),生成两种通道描述符:
- $F_{\mathrm{avg}}^c$(均值池化):捕捉全局上下文信息
- $F_{\text {max }}^c$(最大值池化):提取显著局部特征
2.共享MLP处理:
-将双路描述符输入共享权重的双层MLP(含ReLU激活),输出相加后经Sigmoid生成通道权重 $M_c \in \mathbb{R}^{C \times 1 \times 1}$
- 公式为:$M_c(F)=\sigma(\operatorname{MLP}(\operatorname{GAP}(F))+\operatorname{MLP}(\operatorname{GMP}(F)))$
- 设计动机:实验表明联合使用GAP和GMP比单一池化(如SENet仅用GAP)能生成更精细的注意力图,Top-1错误率降低 $0.34 \%$。
3.特征重标定:将权重 $M_c$ 与原始特征逐通道相乘,实现自适应特征增强。
创新点:
- 双池化互补性:GAP保留整体分布,GMP聚焦关键区域,联合使用可避免SENet的信息损失。
- 轻量化设计:MLP隐藏层维度为 $C / r \quad(r=16)$ ,参数量仅增加 0.14 M (ResNet50为例)。
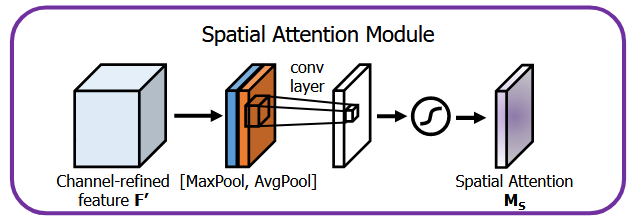
Spatial Attention Module(空间注意力模块)
原理:
空间注意力模块用于强调特征图的空间显著区域,与通道注意力形成互补:
1.双路通道压缩:
-对通道注意力输出 $F^{\prime} \in \mathbb{R}^{C \times H \times W}$ 沿通道轴分别进行平均池化(CAP)和最大池化(CMP),生成两个2D空间描述符:
- $F_{\mathrm{avg}}^s \in \mathbb{R}^{1 \times H \times W}$ :平滑的空间统计信息
- $F_{\text {max }}^s \in \mathbb{R}^{1 \times H \times W}$ :突出的空间响应
2.空间权重生成:
-将双路描述符拼接为 $2 \times H \times W$ 的特征,经 $7 \times 7$ 卷积降维至单通道后通过Sigmoid生成空间权重 $M_s \in \mathbb{R}^{1 \times H \times W}$ 。公式为:$M_s\left(F^{\prime}\right)=\sigma\left(f_{7 \times 7}\left(\left[\operatorname{CAP}\left(F^{\prime}\right) ; \operatorname{CMP}\left(F^{\prime}\right)\right]\right)\right)$
-设计动机:大卷积核( $7 \times 7$ )能捕获广域空间关系,实验表明其比 $3 \times 3$ 卷积降低Top- 1 错误率 $0.22 \%$。
3.特征重标定:将权重 $M_s$ 与输入特征逐位置相乘,强化目标区域响应。
创新点:
-通道-空间协同:先通过通道注意力解决"what"(语义重要性),再通过空间注意力定位"where"(空间显著性),两者串联比并行效果更优(错误率降低 $0.12 \%$ ,见表3)。
-高效性:仅增加 1 个 $7 \times 7$ 卷积层,计算开销可忽略(ResNet50仅增加0.004 GFLOPs)。
结论
-
本研究提出CBAM模块,通过联合优化通道与空间注意力机制,为CNN特征表示提供了一种轻量级通用增强方案,在保持计算效率的同时显著提升模型性能
-
优点:
-
双注意力机制比单一通道注意力(如SENet)具有更精细的特征选择能力
-
即插即用设计兼容主流CNN架构
局限:
未讨论模块在超深网络(如ResNet152+)中的可扩展性
主要结论:
-
- 联合使用max-pooling与average-pooling的通道注意力模块比SENet产生更精确的注意力图
- 空间注意力模块通过7×7卷积有效捕捉位置重要性,与通道注意力形成互补
- 在ImageNet-1K、MS COCO和VOC 2007三大基准测试中均超越基线模型
- 可视化证实模块能引导网络准确聚焦目标物体区域
Pytorch code
import torch
import torch.nn as nn
import torch.nn.functional as F
class CBAM(nn.Module):
def __init__(self, in_channels, reduction_ratio=16, kernel_size=7):
"""
CBAM 模块实现
Args:
in_channels: 输入特征图的通道数
reduction_ratio: 通道注意力中的压缩比例
kernel_size: 空间注意力中的卷积核大小
"""
super(CBAM, self).__init__()
# 通道注意力模块
self.channel_attention = ChannelAttention(in_channels, reduction_ratio)
# 空间注意力模块
self.spatial_attention = SpatialAttention(kernel_size)
def forward(self, x):
# 先应用通道注意力
x = self.channel_attention(x)
# 再应用空间注意力
x = self.spatial_attention(x)
return x
class ChannelAttention(nn.Module):
def __init__(self, in_channels, reduction_ratio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
# 共享MLP
self.mlp = nn.Sequential(
nn.Conv2d(in_channels, in_channels // reduction_ratio, 1, bias=False),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels // reduction_ratio, in_channels, 1, bias=False)
)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
# 平均池化分支
avg_out = self.mlp(self.avg_pool(x))
# 最大池化分支
max_out = self.mlp(self.max_pool(x))
# 合并分支
channel_weights = self.sigmoid(avg_out + max_out)
return x * channel_weights
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3, 7), "kernel size must be 3 or 7"
padding = 3 if kernel_size == 7 else 1
self.conv = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
# 沿通道维度计算平均值和最大值
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
# 拼接特征
combined = torch.cat([avg_out, max_out], dim=1)
# 生成空间注意力图
spatial_weights = self.sigmoid(self.conv(combined))
return x * spatial_weights
# ------------------- 用法示例 -------------------
if __name__ == "__main__":
# 1. 初始化CBAM模块(输入通道数为256,压缩比例16)
cbam = CBAM(in_channels=256, reduction_ratio=16)
# 2. 模拟输入数据(batch_size=4, 通道=256, 特征图尺寸=56x56)
dummy_input = torch.randn(4, 256, 56, 56)
# 3. 前向传播
output = cbam(dummy_input)
print(f"输入形状: {dummy_input.shape}")
print(f"输出形状: {output.shape}") # 应与输入形状一致作者
arwin.yu.98@gmail.com





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}