
基本信息
- 📰标题: Attentional Feature Fusion
- 🖋️作者: Yimian Dai
- 🏛️机构: Nanjing University of Science and Technology (南京理工大学)
- 🔥关键词: Feature Fusion, Attention Mechanism, Multi-Scale, Deep Learning
摘要概述
| 项目 | 内容 |
|---|---|
| 📖研究背景 | 现有特征融合方法(如线性相加/拼接)在跨层和多尺度场景下存在语义不一致和动态适应性不足的问题。 |
| 🎯研究目的 | 提出统一框架以优化特征融合,解决初始对齐和多尺度上下文聚合的挑战。 |
| ✍️研究方法 | 设计AFF模块(动态注意力融合)和MS-CAM(多尺度通道注意力),结合迭代优化(iAFF)。 |
| 🕊️研究对象 | 深度神经网络中的同层/跨层特征融合(如ResNet、FPN等)。 |
| 🔍研究结论 | AFF/iAFF显著提升多尺度目标(尤其小物体)的判别力,且参数量更优;初始融合质量是关键瓶颈。 |
| ⭐创新点 | 1. 首次将注意力泛化至全场景融合;2. MS-CAM通过多池化增强尺度感知;3. 迭代注意力优化初始融合。 |
背景
研究背景:
卷积神经网络(CNN)通过增加深度、宽度、基数或动态优化特征显著提升了表征能力,但特征融合作为网络核心组件仍依赖简单的线性操作(如相加/拼接),无法适应跨层/多尺度场景下的语义不一致问题。现有工作(如InceptionNet、ResNet、FPN)虽广泛使用特征融合,但多聚焦于路径设计而非融合方法本身。
过去方案:
-
传统方法:线性融合(加法/拼接)缺乏动态适应性,难以处理特征尺度与语义差异。
-
注意力改进:SKNet和ResNeSt引入通道注意力实现同层特征动态加权,但存在三大局限:
- 仅适用于同层融合,跨层场景(如skip connections)未解决;
- 初始融合(如简单相加)成为性能瓶颈;
- 全局通道注意力偏向大目标,忽视多尺度上下文。
研究动机:
针对上述缺陷,本文提出:
-
统一框架需求:亟需一种通用方法统一同层/跨层特征融合;
-
动态优化必要性:需同时解决初始融合质量与多尺度上下文聚合问题;
-
小目标敏感度:通过多尺度通道注意力(MS-CAM)增强对极端尺度(尤其小物体)的判别力。
方法
-
理论背景:
本研究基于特征融合的动态优化理论,指出传统线性融合(如相加/拼接)因缺乏语义感知能力导致跨层/多尺度特征对齐失效。核心理论支撑包括:
(1)注意力机制的特征选择特性(参考SENet);
(2)多尺度上下文建模的必要性(参考Inception模块);
(3)迭代优化对初始融合偏差的修正作用(参考残差学习思想)。 -
技术路线:
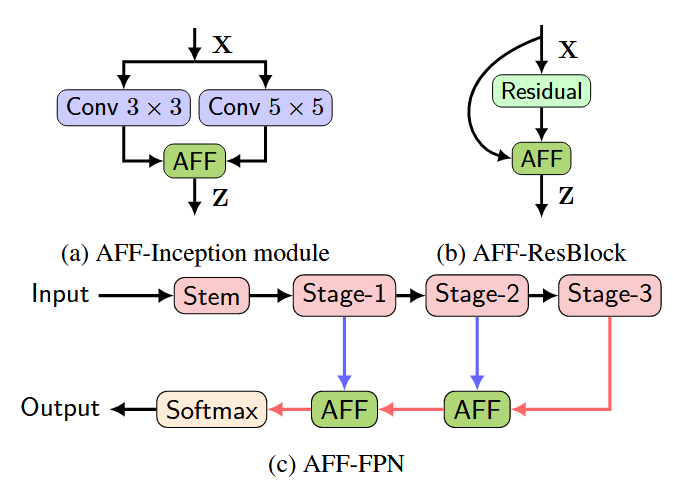
1. 框架设计:构建通用注意力特征融合(AFF)模块,通过特征拼接→通道注意力→空间重加权实现动态融合:
AFF模块分为三个关键阶段:
1.初始特征整合(Initial Integration)
。输入两个待融合的特征图 $X$ 和 $Y$(例如同层的多尺度特征或跨层跳跃连接特征),默认 $Y$ 具有更大的感受野。
-通过元素相加 $(\oplus)$ 或拼接 $(\uplus)$ 进行初始整合,生成中间特征 $X \oplus Y$。
2.多尺度通道注意力(MS-CAM)
- 对初始整合后的特征应用多尺度通道注意力模块(MS-CAM):
- 全局上下文:通过全局平均池化(GAP)压缩空间维度,生成通道级全局描述符 $g(X \oplus Y)$ 。
- 局部上下文:通过点卷积(PWConv)提取逐像素的局部通道交互特征 $L(X \oplus Y$ ),保留细节信息。
- 动态权重生成:将全局与局部上下文相加后经Sigmoid激活,生成注意力权重
$$
M(X \oplus Y) \in[0,1]^{C \times H \times W} \quad
$$
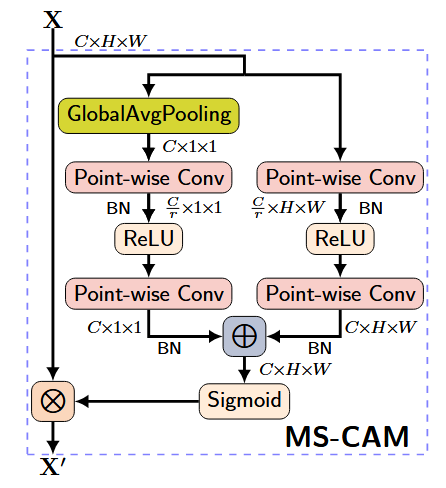
3.软选择融合(Soft Selection)
-使用注意力权重对输入特征进行加权求和:$Z=M(X \oplus Y) \otimes X+(1-M(X \oplus Y)) \otimes Y$ 其中 $\otimes$ 为逐元素乘法,实现特征的自适应融合。
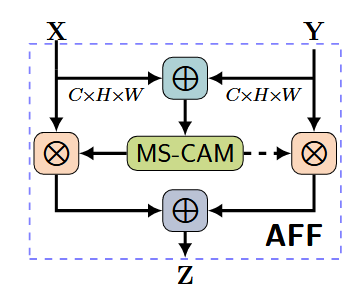
迭代优化:在AFF基础上引入iAFF结构,通过递归注意力机制渐进修正初始融合误差;
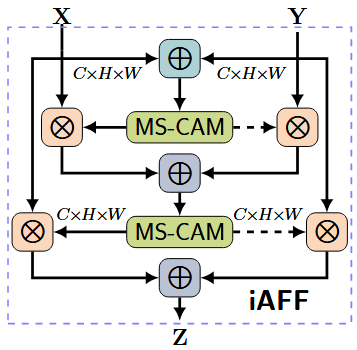
- 两级注意力机制:第一级AFF模块生成初步融合特征 $X \oplus Y$ ,第二级AFF进一步优化融合权重。
- 公式化表示为:
$$
X \oplus Y=M_1(X+Y) \otimes X+\left(1-M_1(X+Y)\right) \otimes Y Z=M_2(X \oplus Y) \otimes X+\left(1-M_2(X \oplus Y)\right) \otimes Y
$$
实验表明iAFF在ImageNet上比单级AFF提升 $0.5 \%$ 准确率。
兼容性扩展:适配同层(Inception)、短跳连(ResNet)、长跳连(FPN)三类典型融合场景。
结论
-
本研究将attention机制拓展为特征融合的通用动态选择框架,解决了跨层/多尺度场景下的语义对齐问题,为深度神经网络的特征融合设计提供了新范式。
-
优点:提出的MS-CAM模块通过融合局部与全局通道上下文显著提升多尺度感知能力;iAFF结构首次系统解决初始融合质量瓶颈。
-
缺点:未讨论计算复杂度与实时性权衡,且实验仅基于图像分类任务验证。
主要结论:
- Attention机制可泛化为同层/跨层特征融合的统一解决方案;
- MS-CAM通过多尺度通道统计有效缓解语义与尺度不一致性;
- 初始融合质量是attention-based融合的关键瓶颈,迭代注意力(iAFF)可显著优化;
- 在CIFAR-100/ImageNet上以更少参数量超越SOTA,验证了精细化特征融合的潜力。
Pytorch code
import torch
import torch.nn as nn
import torch.nn.functional as F
class MSCAM(nn.Module):
def __init__(self, channels=64, r=4):
super(MSCAM, self).__init__()
inter_channels = int(channels // r)
# 局部注意力
self.local_att = nn.Sequential(
nn.Conv2d(channels, inter_channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(inter_channels),
nn.ReLU(inplace=True),
nn.Conv2d(inter_channels, channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(channels),
)
# 全局注意力 - 移除了BatchNorm以避免1x1输入的问题
self.global_att = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(channels, inter_channels, kernel_size=1, stride=1, padding=0),
nn.ReLU(inplace=True),
nn.Conv2d(inter_channels, channels, kernel_size=1, stride=1, padding=0),
)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
xl = self.local_att(x)
xg = self.global_att(x)
xlg = xl + xg
wei = self.sigmoid(xlg)
return wei
class AFF(nn.Module):
def __init__(self, channels=64, r=4):
super(AFF, self).__init__()
self.MSCAM = MSCAM(channels, r) # 输入通道是channels(相加后)
def forward(self, x, y):
xy = x + y
wei = self.MSCAM(xy)
# 加权融合
xo = x * wei + y * (1 - wei)
return xo
class iAFF(nn.Module):
def __init__(self, channels=64, r=4):
super(iAFF, self).__init__()
# 第一阶段特征融合
self.AFF1 = AFF(channels, r)
# 第二阶段特征融合
self.AFF2 = AFF(channels, r)
def forward(self, x, y):
# 第一阶段融合
z = self.AFF1(x, y)
# 第二阶段融合
z = self.AFF2(x, z)
return z
# ------------------- 用法示例 -------------------
if __name__ == "__main__":
# 初始化
aff = AFF(channels=64)
iaff = iAFF(channels=64)
# 假设有两个特征图
x = torch.randn(1, 64, 32, 32)
y = torch.randn(1, 64, 32, 32)
# 使用AFF
out_aff = aff(x, y)
# 使用iAFF
out_iaff = iaff(x, y)
print(f"输入形状: {x.shape}")
print(f"输出形状: {out_iaff.shape}") # 应与输入形状一致作者
arwin.yu.98@gmail.com




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}