
1. 引言
近年来,语言、视觉和多模态预训练技术正加速融合,仿佛AI领域的"三国归一"。在这场变革中,BEIT-3横空出世——一个号称"通用多模态基础模型"的全能选手,不仅在图像识别、文本理解等单模态任务上表现惊艳,还能轻松玩转图文问答、跨模态检索等复杂挑战。
🔧 三大创新:如何实现"大一统"?
- 灵活的多路Transformer架构
- 像乐高一样模块化:既能针对不同数据类型(文字/图片)定制化编码,又能实现深度的跨模态融合。
- 就像同一位翻译官,既能流利处理中文和英文,还能理解"表情包+文字"的混合梗。
- 统一的掩码预训练
- 无论处理图片(Imglish)、文本(English)还是图文对("parallel sentences"),模型都通过遮盖预测学习——好比让AI玩"填空游戏",通过补全缺失的像素或单词来理解世界。
- 关键突破:同一套方法处理所有模态,打破传统多模态模型"拼凑感"的局限。
- 规模化的力量
- 更大的数据+更大的模型=更强的通用性。BEIT-3证明:当参数规模突破临界点,模型会涌现出跨模态的"通感"能力。
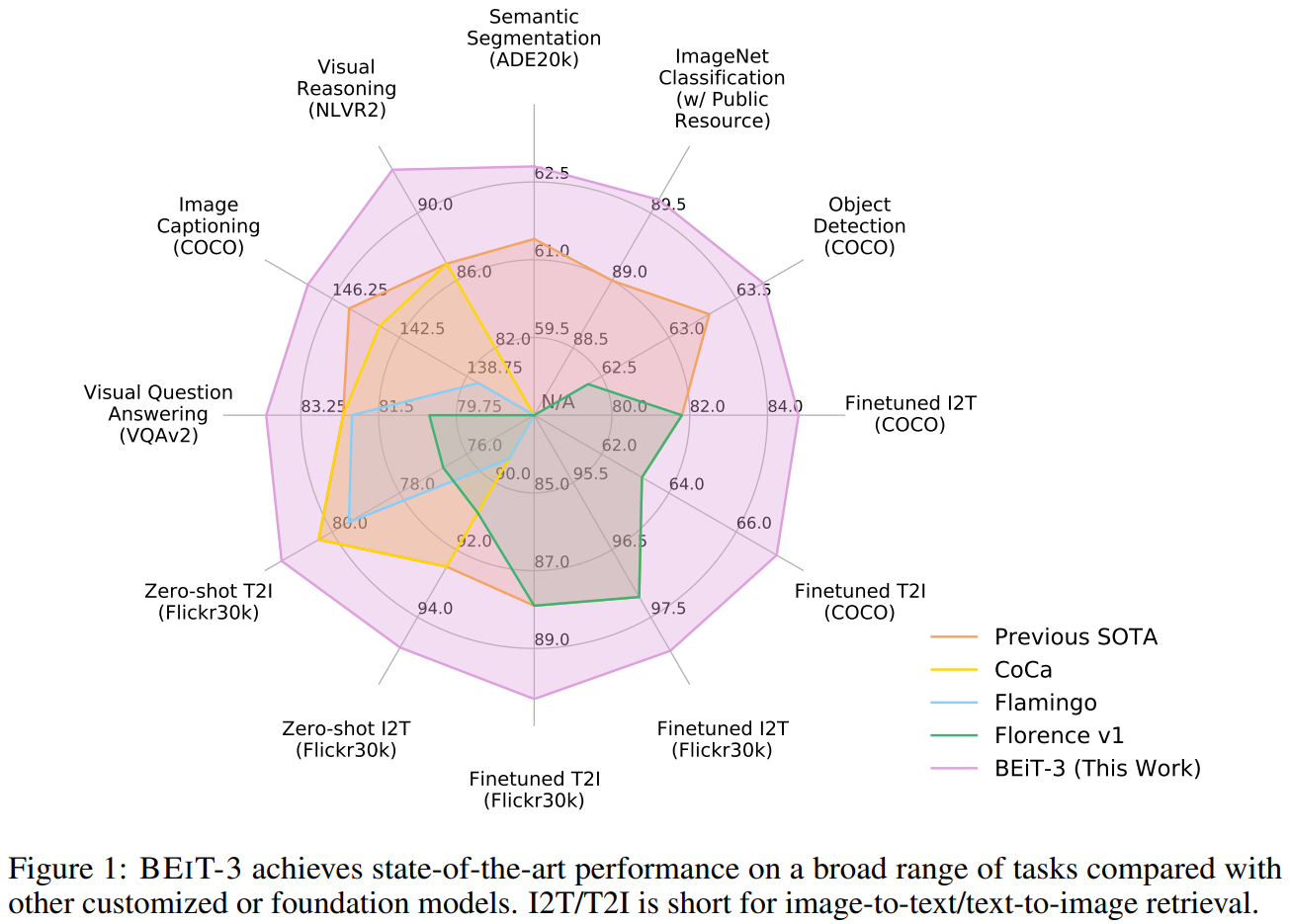
🏆 实战成绩单:屠榜多模态任务
在8项权威测试中,BEIT-3全部刷新纪录:
- 视觉领域:目标检测(COCO)、图像分割(ADE20K)、分类(ImageNet)
- 语言-视觉交互:视觉推理(NLVR2)、图文问答(VQAv2)、图像描述生成(COCO)
- 跨模态搜索:以图搜文/以文搜图(Flickr30K/COCO)
类似CoCa工作,BEiT-3的作者团队也给出了一张非常直观且夸张的性能图,如下所示:
2. 相关工作
2.1 模型架构
在视觉-语言任务中,Transformer 的应用方式多种多样,取决于具体需求:
- 双编码器(Dual-Encoder):
- 适合高效检索(比如以图搜文、以文搜图)。
- 特点:速度快,适合海量数据匹配,但交互较浅。
- 代表工作:CLIP...
- 编码器-解码器(Encoder-Decoder):
- 擅长生成任务(如图像描述生成、视觉问答)。
- 类比:像一个人先“看懂”图片,再用语言描述出来。
- 代表工作:SimVLM,ALBEF, BLIP...
- 融合编码器(Fusion-Encoder):
- 专精深度图文理解(比如复杂推理任务)。
- 优势:能捕捉更精细的跨模态关联,但计算成本高。
- 代表工作:ViLT,VLMP,BEiT-3...
⚠️ 现有方法的痛点
虽然这些架构各有优势,但大多数基础模型(Foundation Models)面临两大问题:
- 任务适配麻烦:不同下游任务需要手动调整模型结构,就像每换一个游戏就要重新组装手柄。
- 参数共享不足:模态之间“各练各的”,导致模型无法真正融会贯通。
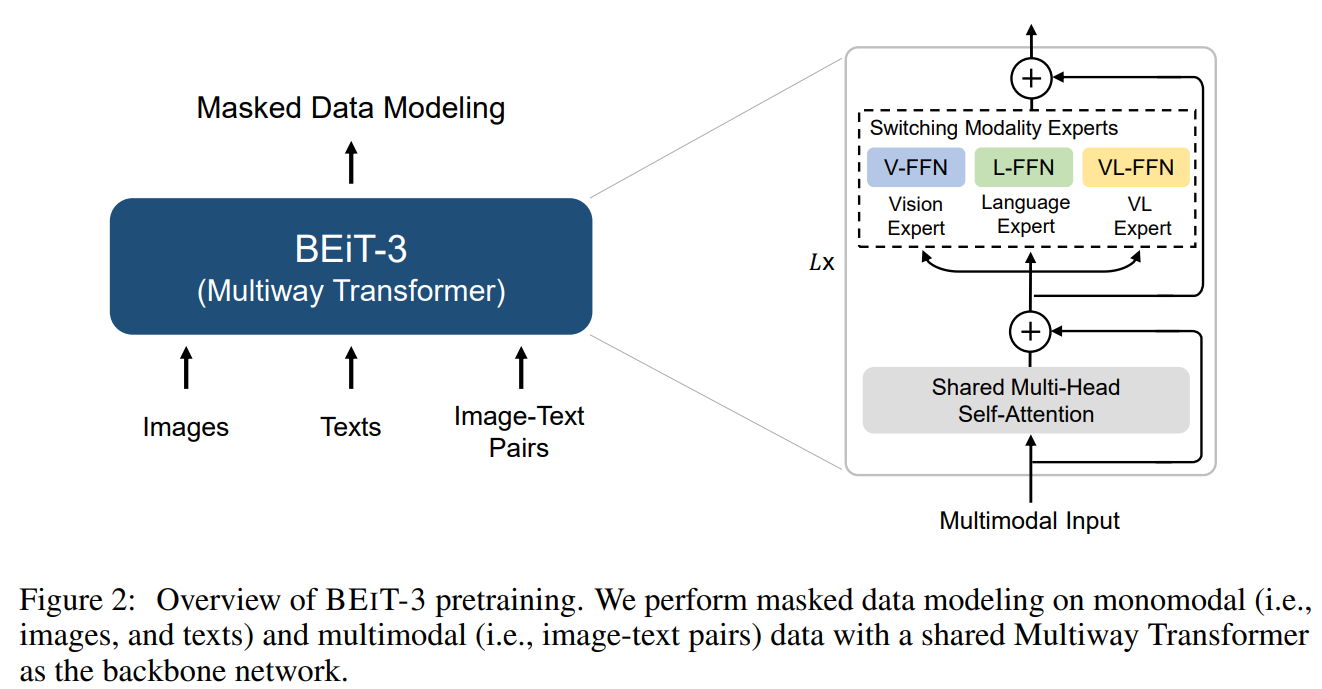
BEIT-3 的解决方案:多路 Transformer(Multiway Transformers)
我们的方法采用统一架构,一套模型适应各种任务,同时兼顾:
- 模态专属编码(让文本和图像各自保留特性)
- 跨模态深度融合(让它们能高效协作)
- 实际上就是VLMO中的混合专家模式MoE.
关键优势:
✅ 参数共享更高效 – 不同模态互相促进,而非孤立学习
✅ 任务适配更灵活 – 无需为每个应用重新设计模型
✅ 性能更强 – 实验证明,统一架构反而能提升各项任务的表现
在现实场景中,我们往往需要 AI 同时处理多种任务(比如智能客服既要理解文字,又要分析用户上传的截图)。如果每个任务都需专用模型,不仅成本高,而且难以协同优化。BEIT-3 的统一架构或许正是未来大模型的发展方向——少一点定制,多一点通用。
类比:就像智能手机取代了相机、MP3、地图和计算器,未来的 AI 模型可能也会走向“All in One”。
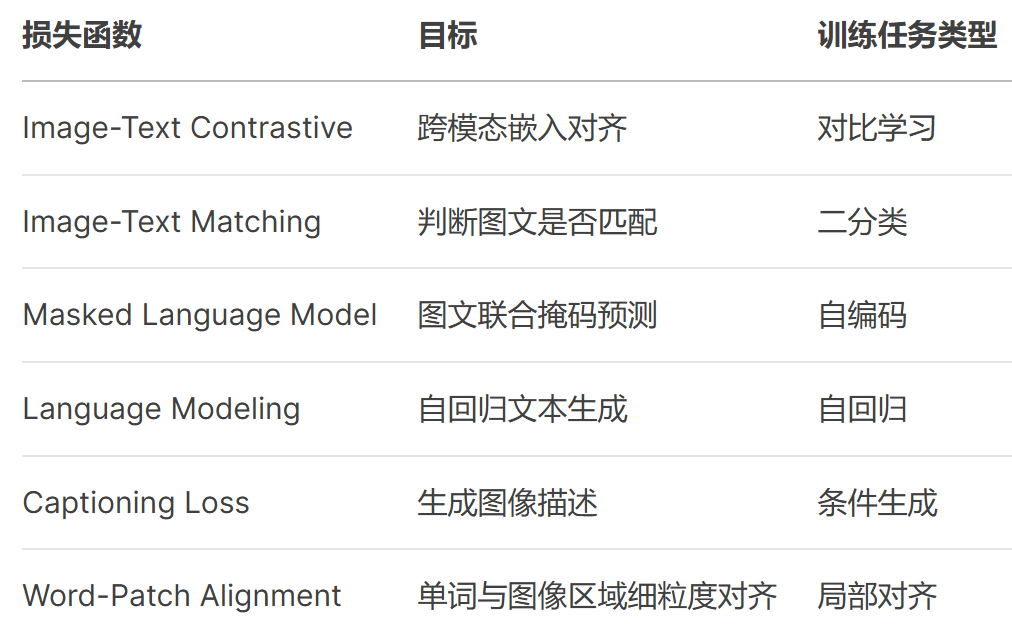
2.2 训练目标与损失函数
在AI界,掩码预训练(mask-then-predict)早已不是新鲜事——BERT靠它读懂了文本,MAE靠它理解了图像。但BEIT-3做了一件大胆的事:用同一种「填空」方式,同时训练文字、图片和图文对。
- 文本(English):遮盖单词让模型预测(如「___ 是人工智能的核心技术」)
- 图像(Imglish):遮盖图像区块让模型补全(如马赛克部分画面)
- 图文对(Parallel Sentences):将配对的图文视为「双语对照」,让模型学习跨模态对齐
传统多模态模型要同时训练多个任务(如图文匹配、对比学习),而BEIT-3只需专注「填空」这一核心能力,训练效率大幅提升,化繁为简。另一方面,把图像视为「外语」(Imglish),让模型用处理文本的思维处理像素——就像人类既能「读」文字也能「读」图。实验证明,这种简单方法学到的表征,竟能通杀图像分类、视觉推理、图文生成等复杂任务!
下面列举一些视觉-文本多模态模型训练中常见的训练目标:
2.3 模型缩放
BEIT-3延续了大模型的黄金法则:更多参数+更多数据=更强通用性。但它的特别之处在于:
- 参数规模:达到数十亿级别,但通过统一架构避免冗余
- 数据规模:仅使用公开数据集(学术友好!),却通过高效训练方法榨取最大价值
关键发现:
- 模型越大,跨模态的「通感」能力越强——比如看到「落日照片」时,不仅能描述画面,还能联想到相关诗句。
- 数据多样性比单纯堆量更重要:BEIT-3的图文对包含抽象艺术、科学图解等,迫使模型建立深层关联。
💡 启示:少即是多?
BEIT-3挑战了一个常见误区:多任务损失函数≠更好性能。它的成功暗示:
- 专注核心目标(生成式预训练)可能比「花式调参」更有效
- 统一表征空间是跨模态理解的钥匙——就像人类大脑不会为文字和图像准备两套处理机制
3. 模型结构
BEiT-3的模型结构实在没什么好讲的,几乎和VLMO是一模一样,详见VLMO博文。
由于Multiway Transformer结构的灵活性,BEiT-3模型在训练好以后可以用于各种不同的下游任务,如图3所示:
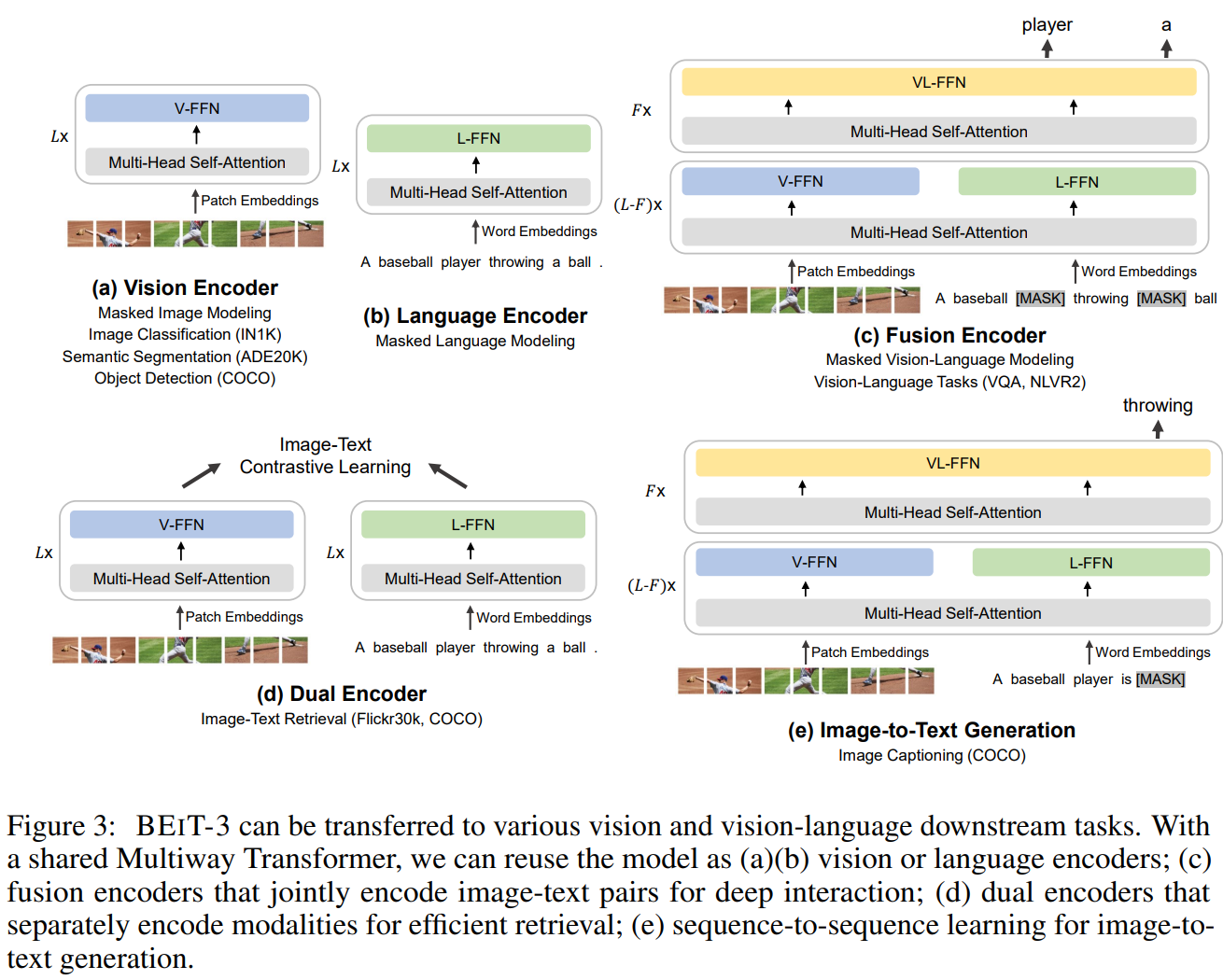
如上图所示,BEiT-3可以通过选择开启或关闭Muliway-Transformer中混合专家的种类来进行不同的任务类型:
- 单模态视觉或文本任务:仅开启MoE中的视觉专家或文本专家即可,如图3(a),(b).
- 理解类任务:在模型靠近输入的前半部分的模块中,开启MoE中的视觉和文本专家;在剩余的后半部分模块中仅开启混合专家,如图3(c)。
- 检索类任务:首先模型仅开启视觉专家处理图像,然后进开启文本专家处理文本,最后计算两个结果的相似度,如图3(d)。
- 生成类任务:与理解类任务一样,如图3(e)。
4. 结论
BEIT-3是一个通用的多模态基础模型,它在众多视觉和视觉-语言基准测试中均取得了最佳性能。BEIT-3 的核心思想是将图像建模为外语,从而能够以统一的方式对图像、文本和图文对进行掩码“语言”建模。BEIT-3还证明了多路 Transformer 能够有效地建模不同的视觉和视觉-语言任务,使其成为通用建模的一个有吸引力的选择。BEIT-3 简单有效,是扩展多模态基础模型的一个有希望的方向。未来的工作中,可以尝试在 BEIT-3 中包含更多模态(例如音频),以促进跨语言和跨模态迁移,并推进跨任务、跨语言和跨模态大规模预训练的融合。
作者
arwin.yu.98@gmail.com





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
1 评论